
Thuật toán K-means.
Thuật tóan K-means hay còn được gọi là thuật toán phân cụm K-means( K-means clustering ). Nó là phương pháp lượng tử hóa vector dùng để phân tích các điểm dữ liệu cho trước vào các cụm khác nhau. (theo wikipedia)
Khái niệm :
- Thuật tóan Kmeans hay còn được gọi là thuật toán phân cụm K-mean.
- Nó là phương pháp lượng tử hóa vector dùng để phân tích các điểm dữ liệu cho trước vào các cụm khác nhau. (theo wikipedia)
Thuật toán chi tiết:
Thuật toán k-means có thể được chia thành các bước như sau:
- Bước 1: Tạo các trung tâm ngẫu nhiên
C(0) = {m(0)1 , m(0)2 , …, m(0)k}
- Bước 2: Gán các điểm dữ liệu vào các cụm
- Với mỗi điểm dữ liệu, ta sẽ tính khoảng cách của nó tới các trung tâm (bằng khoảng cách Euclidean).
- Ta sẽ gán chúng vào trung tâm gần nhất. Tập hợp các điểm được gán vào cùng 1 trung tâm sẽ tạo thành cụm.

- Bước 3:Cập nhật trung tâm
- Với mỗi cụm đã tìm được ở bước 2, trung tâm mới sẽ là trung bình cộng của các điểm dữ liệu trong cụm đó.

Tóm tắt thuật toán:
Đầu vào: Dữ liệu XX và số lượng cluster cần tìm KK.
Đầu ra: Các center MM và label vector cho từng điểm dữ liệu YY.
- Chọn KK điểm bất kỳ làm các center ban đầu.
- Phân mỗi điểm dữ liệu vào cluster có center gần nó nhất.
- Nếu việc gán dữ liệu vào từng cluster ở bước 2 không thay đổi so với vòng lặp trước nó thì ta dừng thuật toán.
- Cập nhật center cho từng cluster bằng cách lấy trung bình cộng của tất các các điểm dữ liệu đã được gán vào cluster đó sau bước 2.
- Quay lại bước 2.
Ví dụ :
Công ty A muốn đón n hành khách. Công ty muốn gon hành khách về k địa điểm để tiện cho việc đón. Giả sử số hành khách là n = 7 và số địa điểm k = 2. Cho vị trí của 7 hành khách(trong không gian 2 chiều) laf: A(2,3), B(4,2), C(7,8), D(6,6), E(4,4), F(8,8), G(3,3). Hãy cho biết tọa độ 2 điểm đón hành khách và nên đón hành khách nạo tại mỗi địa điểm để việc đón khách là thuận tiện nhất.
Giải :
Ta có cơ sở dữ liệu:
| OBJECT | X | Y |
| A | 2 | 3 |
| B | 4 | 2 |
| C | 7 | 8 |
| D | 6 | 6 |
| E | 4 | 4 |
| F | 8 | 8 |
| G | 3 | 3 |
Cho điểm M(a;b) và điểm N(α;β). Khi đó khoảng cách giữa hai điểm M và N được tính theo công thức:
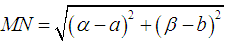
Chọn ra 2 điểm bất kỳ làm tâm của 2 cụm : C1 ≡ A và C2 ≡ B
Áp dụng công thức ta có:
Lần lặp thức1
d(C, C1) = sqrt(50) > d(C, C2) = sqrt(45) như vậy thì C thuộc phân cụm C2.
Tương tự với các Object khác thì ta có : cụm C1(A, G) và cụm C2(B, C, D, E, F)
Kết thúc lần 1:
ta cập nhật lại trọng tâm của 2 cụm với C1 = (x, y) = ((2+3)/2 , (3+3)/2) = (5/3 , 3) và cụm C2 = (x, y) = (29/5 , 28/5)
Lần lặp thứ 2:
Cập nhật khoảng cách từ các điểm tới trọng tâm của các cụm sau khi được cập nhật tại lần 1:
d(A, C1) = 0,5 < d(A, C2) = 3.8 => A thuộc cụm C1
d(B,C1) = 1.8 < d(B, C2) = 2.14 => B thuộc cụm C1
d(C,C1) = 6,73 > d(C, C2) = 5.03 => C thuộc cụm C2
Tương tự với các Object còn lại thì ta được: cụm C1 = {A, B, E, G} và cụm C2 = {C,D,F}
Kết thúc lần lặp thứ 2: ta cập nhật lại vị trí của các trong tâm ( tương tự kết thức lần lặp thứ 1) và thực hiện tiếp theo lần lặp thứ 2 cho đến khi không có sự thay đổi về cụm các Object tồn tại ơ trong mỗi cụm thì kết luận
- Trên đây là bài viết cá nhân của mình về thuật toán K-means có sử dụng taì liệu trên Wikipedia.
- Nếu có sai sót mong mọi người góp ý phía dưới comment.
- Mình xin cảm on.
Bài viết liên quan
Bài viết mới

Buff là gì trên Facebook? Cách buff trên Facebook ...
Ngày đăng: 03-11-2023
FrontEnd Là Gì? BackEnd Là Gì?
Ngày đăng: 17-03-2021
Front End là gì? Lập trình viên Front End giỏi cần...
Ngày đăng: 17-03-2021
Bình luận bài viết